
TL;DR: Key GDPR Risks When Using LLM APIs
Before diving into provider specifics, here is what matters most:
- Personal data is broader than you think. Support tickets, invoice text, chat logs, CRM notes, and HR-adjacent content often contain identifiers that make individuals identifiable under GDPR.
- EU hosting alone is not enough. You must verify actual processing geography, subprocessor access patterns, and transfer mechanisms—not just where data is stored.
- Retention and logging vary by product tier. Default abuse-monitoring logs, application state, and cached content can persist even when training is disabled.
- Compliance depends on configuration, not provider badges. The same provider can be defensible or problematic depending on which product mode, region setting, and contractual controls you use.
- Your architecture matters as much as the provider. Pre-processing, redaction, scoped retrieval, and access controls on your side determine how much risk reaches the API in the first place.
What Counts as Personal Data in LLM Systems
Under GDPR, personal data means any information relating to an identified or identifiable person. This includes names and email addresses, but also online identifiers, IP addresses, and any combination of details that could identify someone indirectly.
In typical LLM workflows, personal data can appear in several places:
- Prompts: Support tickets, customer complaints, internal emails, contract excerpts, HR queries
- System context: Retrieved documents, CRM records, invoice lines, meeting notes used for grounding
- Outputs: Generated text that references individuals from the input
- Logs: Application logs, provider abuse-monitoring logs, cached responses, thread history
The practical test is simple: if your LLM workflow touches text that mentions or describes real people, you are probably processing personal data. This applies even when the data does not look obviously sensitive at first glance.
What Makes an LLM API GDPR Compliant?
There is no GDPR badge for LLM providers. Compliance is not a property of the API itself—it is a property of how you use it, what controls are in place, and whether you can demonstrate accountability if something goes wrong.
The core requirements are:
Lawful basis for processing. You need a valid legal ground under GDPR to process personal data through an LLM. For most business systems, this is either contract performance (the data is necessary to deliver a service) or legitimate interest (with a proper balancing test). Consent is rarely practical for internal workflows.
Data minimisation and purpose limitation. Send only what is necessary. If a support ticket contains a customer name but you only need the issue description, strip the identifier before it reaches the API. Purpose limitation means you cannot use data collected for one purpose (customer support) for an unrelated purpose (model training) without a separate legal basis.
Processor relationship and DPA. When you use an LLM API, the provider typically acts as a data processor on your behalf. This requires a Data Processing Addendum that specifies processing instructions, security obligations, subprocessor lists, and deletion procedures.
Retention control. You must know how long prompts, responses, and logs are kept—by the provider and by your own systems. Default abuse-monitoring retention can be 30 to 55 days depending on the provider, even when training is disabled.
Transfer legality. If data leaves the EU, you need a valid transfer mechanism: adequacy decision, Standard Contractual Clauses, or Binding Corporate Rules. The EU-US Data Privacy Framework provides adequacy for certified US companies, but you should verify certification status and understand that subprocessor chains can still matter.
Demonstrable accountability. If a regulator or data subject asks how you processed their data, you need to be able to answer. This means documented flows, configured retention, auditable access, and clear processor relationships.
Which LLM Providers Are GDPR Compliant?
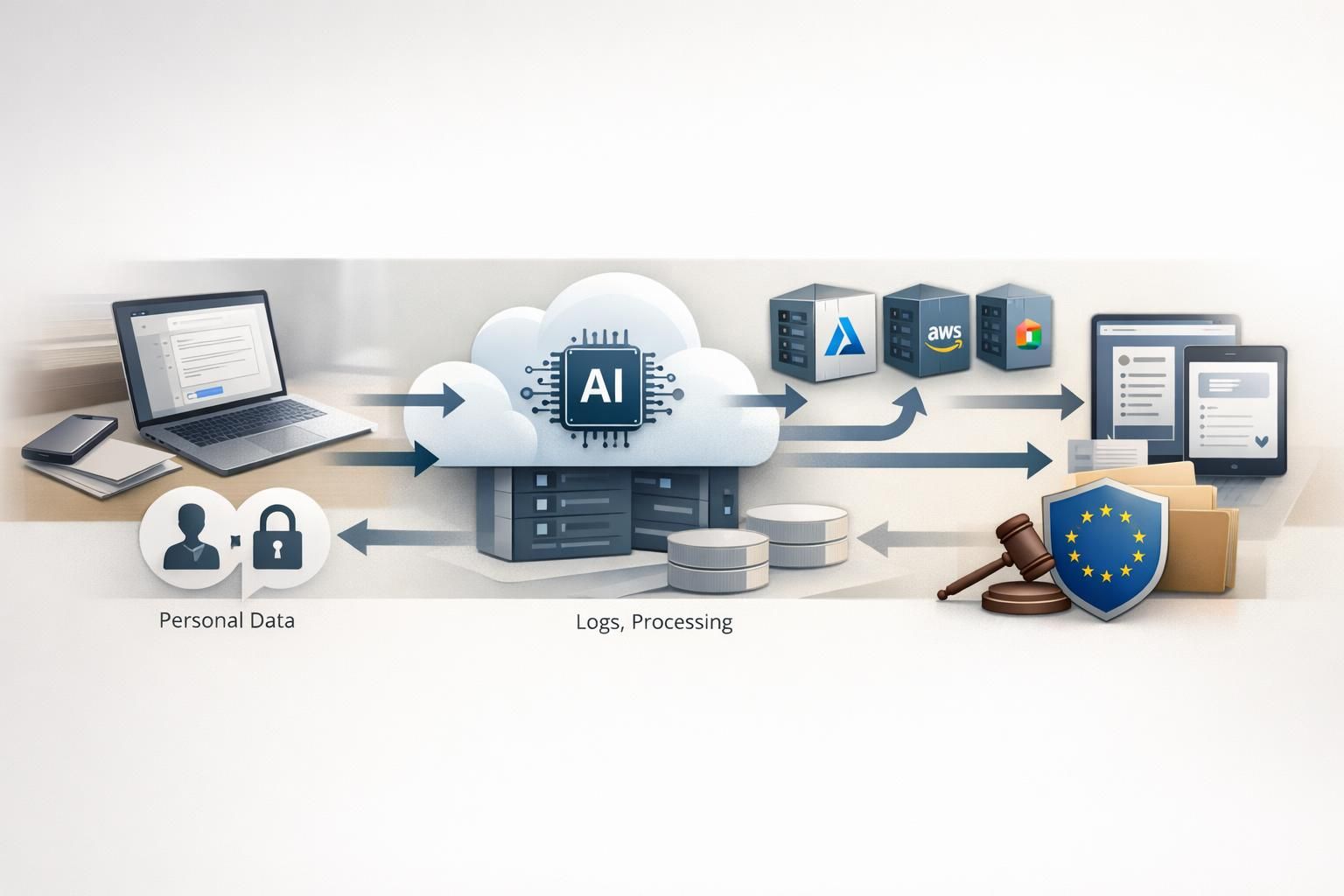
The honest answer is: it depends on which product mode you use and how you configure it.
All major providers offer some path to GDPR-defensible use. But the default configurations, retention behavior, and geographic controls differ significantly. The comparison below focuses on the compliance-relevant differences rather than model capabilities.
Is Azure OpenAI GDPR Compliant?
Azure OpenAI offers the most explicit geography controls among the major options. Microsoft publishes detailed documentation on data handling and operates under Microsoft's enterprise DPA.
Key points:
- No training on prompts: Microsoft states that prompts and completions are not used to train base models and are not available to OpenAI or other providers.
- Geography modes matter: Standard deployments process data within your specified geography. Global deployments may process in any geography where the model is deployed. DataZone deployments process anywhere within a specified zone. This distinction is easy to miss during setup.
- Abuse monitoring: By default, prompts flagged for potential abuse may be stored and reviewed by authorized Microsoft employees. For EEA deployments, reviewers are located in the EEA. Approved customers can request modified abuse monitoring to avoid this storage-plus-review process.
- DPA and subprocessors: Microsoft provides standard enterprise DPA terms and a published subprocessor list.
Azure is a strong option for teams that need explicit EU processing guarantees, but you must choose the right deployment mode and understand that abuse monitoring behavior requires configuration for strictest requirements.
Is OpenAI API GDPR Compliant?
OpenAI has materially improved its enterprise story since 2023. The API now offers Europe-region projects with in-region handling for eligible customers.
Key points:
- No training by default: API data is not used for training unless you explicitly opt in.
- Retention for abuse monitoring: By default, prompts are logged for abuse monitoring and retained for up to 30 days. This applies even when training is disabled.
- Zero data retention: Eligible customers can apply for zero data retention, which eliminates both training use and abuse-monitoring retention. This is not automatic—it requires eligibility verification.
- Europe-region projects: Eligible customers can create new projects with Europe-region handling, keeping data in-region with zero retention. This only applies to new projects created with that setting, not retroactively.
- DPA available: OpenAI publishes a DPA and subprocessor list for business and enterprise customers.
OpenAI API can be GDPR-defensible with the right configuration, but teams with strict requirements should verify eligibility for Europe-region and zero-retention modes before assuming they apply.
Is AWS Bedrock GDPR Compliant?
AWS Bedrock makes the simplest default claim: prompts and completions are not stored or logged by AWS, not used for training, and not shared with model providers after delivery.
Key points:
- No prompt storage: AWS documentation states that Bedrock does not store or log prompts and completions.
- No training: Your data is not used to train AWS models or shared with third-party model providers.
- Routing modes: Bedrock supports in-region, geographic cross-region, and global routing. A team with EU constraints should not assume the default routing mode is acceptable—verify your configuration.
- Region availability: Not all models are available in all regions. If you need a specific model in eu-west-1, check availability before architectural commitment.
- DPA: AWS provides standard enterprise DPA terms under the AWS Data Processing Addendum.
Bedrock is often the cleanest option for teams that want minimal provider-side retention, but routing mode and model availability require attention.
Google Options: Vertex AI vs Gemini API
Google offers two distinct paths with different compliance postures.
Vertex AI (Google Cloud) is the enterprise option:
- Operates under Google Cloud processor terms and DPA
- Google states it will not use customer data to train AI models without permission or instruction
- Zero retention is not a single switch—prompt logging for abuse monitoring, cache behavior for some features, and session-resumption storage up to 24 hours may apply depending on which features you enable
Gemini API / AI Studio is the developer-focused option:
- Abuse-monitoring retention of up to 55 days applies by default
- Grounding features (Search, Maps) have separate retention terms
- Gemini API and AI Studio currently have no fine-tuning-capable model available—Google directs users to Vertex AI for enterprise fine-tuning needs
For strict EU enterprise requirements, Vertex AI under Google Cloud terms is the defensible path. Gemini API is harder to position as the cleanest compliance option without significant caveats.
Provider Comparison: EU Hosting, Retention, and Training
| Provider / Product | EU Hosting Available | Default Prompt Retention | Training on Prompts | Zero-Retention Option |
|---|---|---|---|---|
| Azure OpenAI (Standard) | Yes, geography-specific | Abuse monitoring logs | No | Modified abuse monitoring (approval required) |
| Azure OpenAI (Global) | No, any geography | Abuse monitoring logs | No | Modified abuse monitoring (approval required) |
| OpenAI API | Yes (Europe-region, eligible customers) | Up to 30 days | No (opt-in only) | Yes (eligibility required) |
| AWS Bedrock | Yes (EU regions available) | No prompt storage | No | Default behavior |
| Vertex AI | Yes (region selection) | Feature-dependent | No (without permission) | Feature-by-feature configuration |
| Gemini API | Limited | Up to 55 days | No (abuse monitoring only) | No current zero-retention option |
Where Personal Data Flows: A Practical View
Understanding compliance requires tracing where personal data can appear in your system, not just at the API boundary.
A typical flow looks like this:
User input → Your application → Prompt assembly (retrieval, context) → LLM API call → Provider processing → Response → Your logs, storage, analytics
At each step, personal data can enter, persist, or leak:
- Your application: Chat history, document uploads, user context
- Prompt assembly: Retrieved documents, CRM data, knowledge base excerpts
- Provider side: Abuse monitoring logs, application state, cached responses, file uploads
- Your infrastructure: Response logs, analytics pipelines, audit trails
Provider compliance controls only cover the provider side. Your side of the architecture—what you send, what you log, who can access it—is equally important and entirely your responsibility.
How to Build a GDPR-Compliant LLM Setup
Moving from a prototype to a production-safe system requires deliberate controls:
Data minimisation before the API. Strip identifiers, redact names and emails, anonymise where possible. If you only need the substance of a support ticket, do not send the customer's full contact details.
Scoped retrieval. If you use RAG or document grounding, ensure retrieval respects access boundaries. A user should not receive answers grounded in documents they are not authorised to see.
Retention policy. Define how long prompts, responses, and logs are kept in your systems. Align with your data retention schedule and deletion obligations.
Access control. Limit who can send data to the LLM and who can access logs. Authenticated workflows are easier to audit than open endpoints. A proper identity and access control foundation matters here.
Provider configuration. Select the right region mode, enable zero-retention where available, verify DPA terms, and document your choices.
Audit trail. Log what was sent, when, by whom, and what response was received. This supports accountability and incident response.
Document handling. If users upload documents for LLM processing, ensure ownership boundaries, deletion flows, and storage adapters are configured properly. See how document handling around LLM workflows can be structured.
Fine-Tuning Under GDPR: What Changes

Fine-tuning introduces additional considerations beyond inference:
- Training data provenance: You need to demonstrate lawful basis for using the data in fine-tuning, not just inference.
- Data residency: Where is training data stored during and after fine-tuning? Some providers keep uploaded training data until you delete it.
- Model ownership: Who owns the fine-tuned model? Can you export it? Can you delete it completely?
- Provider restrictions: Google's Gemini API currently has no fine-tuning-capable model available and directs users to Vertex AI. OpenAI and Azure support fine-tuning with documented data handling.
If your team needs GDPR-safer fine-tuning in Europe, the answer is not just pick a provider. Verify whether the enterprise product supports fine-tuning, where training data resides, and whether the model can be deleted on request.
Business Consequences of Getting This Wrong
GDPR compliance in LLM systems is ultimately a business risk question:
Regulatory exposure. Fines under GDPR can reach 4% of global annual turnover. More commonly, enforcement actions trigger reputational damage and operational disruption.
Procurement friction. Enterprise customers increasingly require vendor questionnaires, DPA review, and documented data flows. An unclear LLM setup can delay or block deals.
Audit burden. If you cannot explain how data flows through your LLM system, audits become expensive and time-consuming.
Rework risk. A prototype built on a permissive API configuration may need significant rework when you discover it cannot be used in production with real customer data.
Vendor dependence. Tight coupling to a single provider's specific configuration makes switching costly. A provider-agnostic AI module approach reduces this risk.
Prototype vs Production: What Actually Changes
A quick prototype and a compliant production system are not the same thing:
| Prototype | Production |
|---|---|
| Raw prompts forwarded to API | Pre-send redaction and minimisation |
| Shared API key | Scoped provider configuration per environment |
| Uncontrolled chat history | Explicit retention policy and deletion |
| Document passthrough | Owner-scoped storage with access controls |
| Open chat endpoint | Authenticated, role-based access |
| No logging | Audit trail for accountability |
The gap between these is where compliance risk lives. Many teams discover the gap too late, when a customer asks for a data processing agreement or a regulator asks how personal data is handled.
Making the Provider Decision
When choosing an LLM provider for GDPR-constrained workflows:
- Identify your data sensitivity. What personal data will actually reach the API? Support text, HR content, customer identifiers, financial details?
- Check product mode, not just brand. Azure Global is different from Azure Standard. OpenAI default is different from OpenAI Europe-region with zero retention.
- Verify retention defaults. Understand what is logged, for how long, and whether you can change it.
- Confirm DPA and processor terms. Ensure you have a signed DPA before production use.
- Document your choices. Record which region, which mode, which retention settings, and why.
- Build controls on your side. Provider compliance is necessary but not sufficient. Your architecture determines how much risk reaches the API.
If public cloud APIs are too permissive for your data class, consider hosting your own AI model as an alternative.
For teams that need help building compliant, production-ready AI systems rather than experimental prototypes, implementation support is available.



